library(tidyverse)
library(caret)Presentation 5A: Linear and Logistic Regression
In this section we’ll look at how to define and fit regression models in R.
Load packages
Part1: Linear Regression
We will perform a linear regression using daily cigarettes smoked and exercise level as predictors, \(X\), and lived years as the outcome, \(y\).
Load data
In order to focus on the technical aspects we’ll use a simple toy dataset. It contains the number of cigarettes smoked per day and how long the person lived. It is inspired by this paper if you want to take a look.
df_smoke <- read_csv('../data/smoking_cat.csv')
df_smoke# A tibble: 100 × 3
daily_cigarettes life exercise
<dbl> <dbl> <dbl>
1 7 76 0
2 11 73 0
3 27 72 1
4 23 71 0
5 13 74 0
6 11 76 1
7 20 71 0
8 6 76 1
9 23 72 1
10 32 70 2
# ℹ 90 more rowsWe have daily cigarettes smoked (number) and life (in years). Both of these are numeric variables. We also have a variable named exercise, it seems that this variable might in fact be an ordinal factor variable. Exercise is encoded as a numeric variable, so the first thing we will do is to convert it to a factor.
df_smoke %>%
distinct(exercise)# A tibble: 3 × 1
exercise
<dbl>
1 0
2 1
3 2df_smoke <- df_smoke %>%
mutate(exercise = as.factor(exercise))Split Data into Training and Test Set
Now, we will split our data into a test and a training set. There are numerous ways to do this. We here show sample_frac from dplyr:
# Set seed to ensure reproducibility
set.seed(123)
# add an ID column to keep track of observations
df_smoke$ID <- 1:nrow(df_smoke)
train <- df_smoke %>%
sample_frac(0.70)
nrow(train)[1] 70head(train)# A tibble: 6 × 4
daily_cigarettes life exercise ID
<dbl> <dbl> <fct> <int>
1 29 72 1 31
2 16 73 0 79
3 5 78 1 51
4 3 77 0 14
5 4 79 2 67
6 23 71 1 42As you can see, the ID’s in train are shuffled and it only has 75 rows since we asked for 75% of the data. Now all we have to do is identify the other 25%, i.e. the observations not in train.
#from df_smoke remove what is in train by checking the ID column
test <- df_smoke %>%
filter(!ID %in% train$ID)
# OR
test <- anti_join(df_smoke, train, by = 'ID')
nrow(test)[1] 30head(test)# A tibble: 6 × 4
daily_cigarettes life exercise ID
<dbl> <dbl> <fct> <int>
1 7 76 0 1
2 11 73 0 2
3 27 72 1 3
4 32 70 2 10
5 8 75 0 11
6 25 74 2 19Defining the model
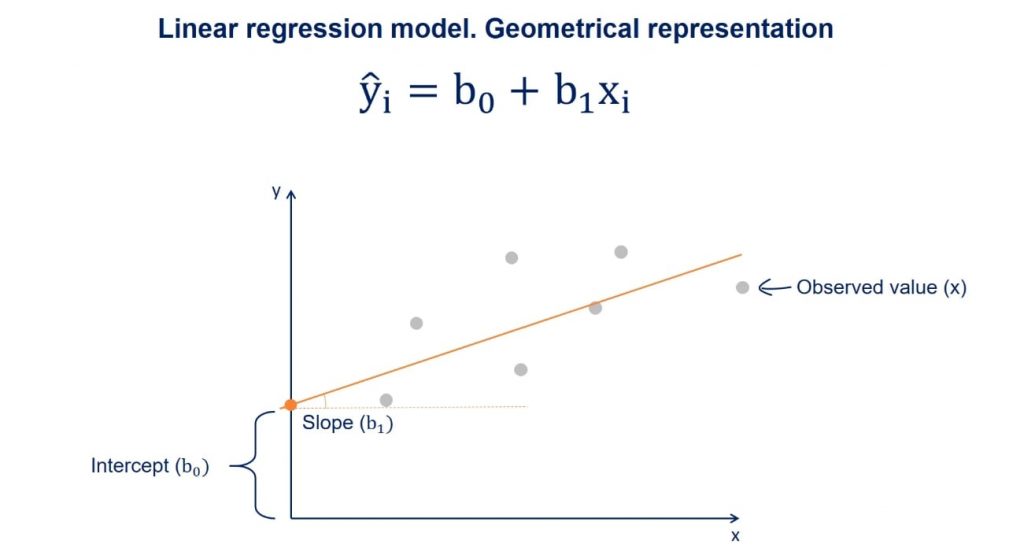
As stated above, a linear regression model generally has the form of:
\[y = β_0 + β_1 * x_i\]
Where we refer to \(β_0\) as the intercept and \(β_1\) as the coefficient. There will typically be one coefficient for each predictor. The goal of modelling is to estimate the values of \(β_0\) and all \(β_i\).
We need to tell R which of our variables is the outcome, \(y\), and which predictors, \(x_i\), we want to include in the model. This is referred to in documentation as the model’s formula. Have a look:
#the formula is written like so:
lm(y ~ x1 + x2 + ..., data = myDataSet)
#see the help
?lmIn our case, \(y\) is the number of years lived and we have a two predictors \(x_1\) (numeric), the number of cigarettes smoked per day, and \(x_2\) (ordinal factor), exercise level (0, 1 or 2). So that will be our model formulation:
#remember to select the training data subset we defined above!
model <- lm(life ~ daily_cigarettes + exercise, data = train)Modelling results
By calling lm we have already trained our model! The return of lm() is, just like the return of prcomp(), a named list.
class(model)[1] "lm"names(model) [1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr" "df.residual"
[9] "contrasts" "xlevels" "call" "terms"
[13] "model" model
Call:
lm(formula = life ~ daily_cigarettes + exercise, data = train)
Coefficients:
(Intercept) daily_cigarettes exercise1 exercise2
77.6514 -0.2881 1.0689 2.3086 Let’s have a look at the results. The summary gives us a lot of information about the model we trained:
# View model summary
summary(model)
Call:
lm(formula = life ~ daily_cigarettes + exercise, data = train)
Residuals:
Min 1Q Median 3Q Max
-1.6514 -0.5153 -0.0586 0.5099 1.6367
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.651375 0.242865 319.731 < 2e-16 ***
daily_cigarettes -0.288086 0.009608 -29.983 < 2e-16 ***
exercise1 1.068900 0.257897 4.145 9.9e-05 ***
exercise2 2.308550 0.270138 8.546 2.8e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8617 on 66 degrees of freedom
Multiple R-squared: 0.9373, Adjusted R-squared: 0.9345
F-statistic: 329 on 3 and 66 DF, p-value: < 2.2e-16The Residuals section summarizes the distribution of the residuals, which is the difference between the actual observed \(y\) values and the fitted \(y\) values.
The Coefficients table shows the estimated values for each coefficient including the intercept, along with their standard errors, t-values, and p-values. These help to determine the significance of each predictor.
In the bottom section we have some information about how well the model fits the training data.
The Residual Standard Error (RSE) is the standard deviation of the residuals (prediction errors). It tells you, on average, how far the observed values deviate from the regression line.
The R-squared value indicates the proportion of variance explained by the model, with the Adjusted R-squared accounting for the number of predictors.
Finally, the F-statistic and its p-value tests whether the model as a whole explains a significant portion of the variance in the response variable (the outcome, \(y\)).
Lets plot the results and IMPORTANTLY check if model assumptions are upheld:
par(mfrow=c(2,2))
plot(model)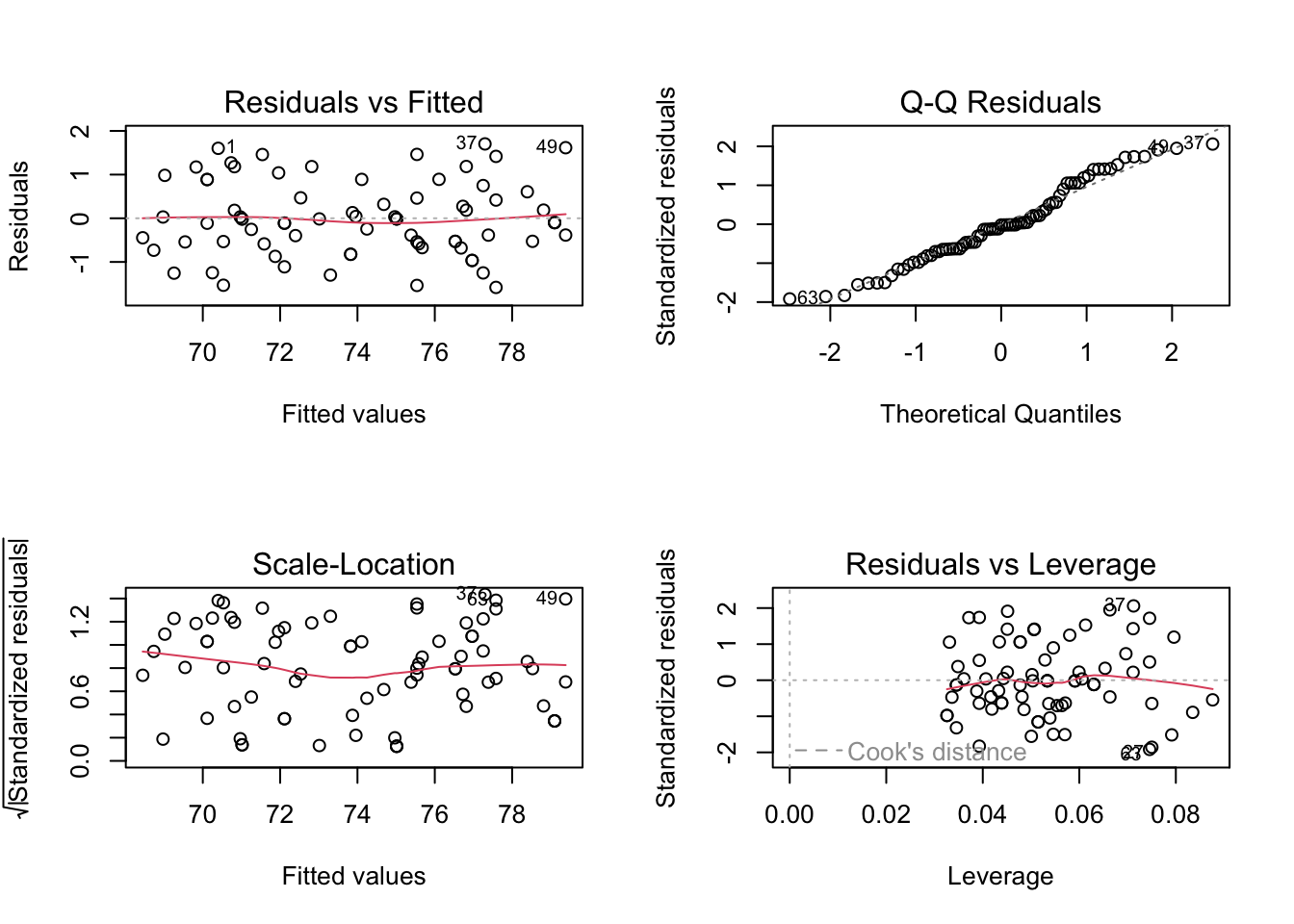
Model interpretation
Now, lets predict the life-expectancy for the individuals in our training data based on our fitted model. For this we will use the predict() function:
Plot to understand the model
What do these results mean? Our model formulation is:
\[life = β_0 + β_1 * cigarettes + β_2 * exercise\]
And we estimated these values:
model$coefficients (Intercept) daily_cigarettes exercise1 exercise2
77.6513748 -0.2880865 1.0689005 2.3085500 Therefore:
The intercept \(β_0\) is the number of years we estimated a person in this dataset will live if they smoke 0 cigarettes and do not exercise. It is 77.6 years.
The coefficient of cigarettes per day is -0.29. This means for every 1 unit increase in cigarettes (one additional cigarette per day) the life expectancy decreases by 0.29 years. Similarly for the exercise variable, if you exercise your life expectancy will go up 1.1-2.4 years compared to no exercise, independently of how many cigarettes you smoke.
Model performance
We now use our held out test data to evaluate the model performance. For that we will predict life expectancy for the 25 observations in test and compare with the observed values.
#use the fitted model to make predictions for the test data
y_pred <- predict(model, newdata = test)Let’s see how the predicted values fit with the observed values.
pred <- tibble(pred = y_pred,
real = test$life)
ggplot(pred,
aes(x=real, y=pred)) +
geom_point()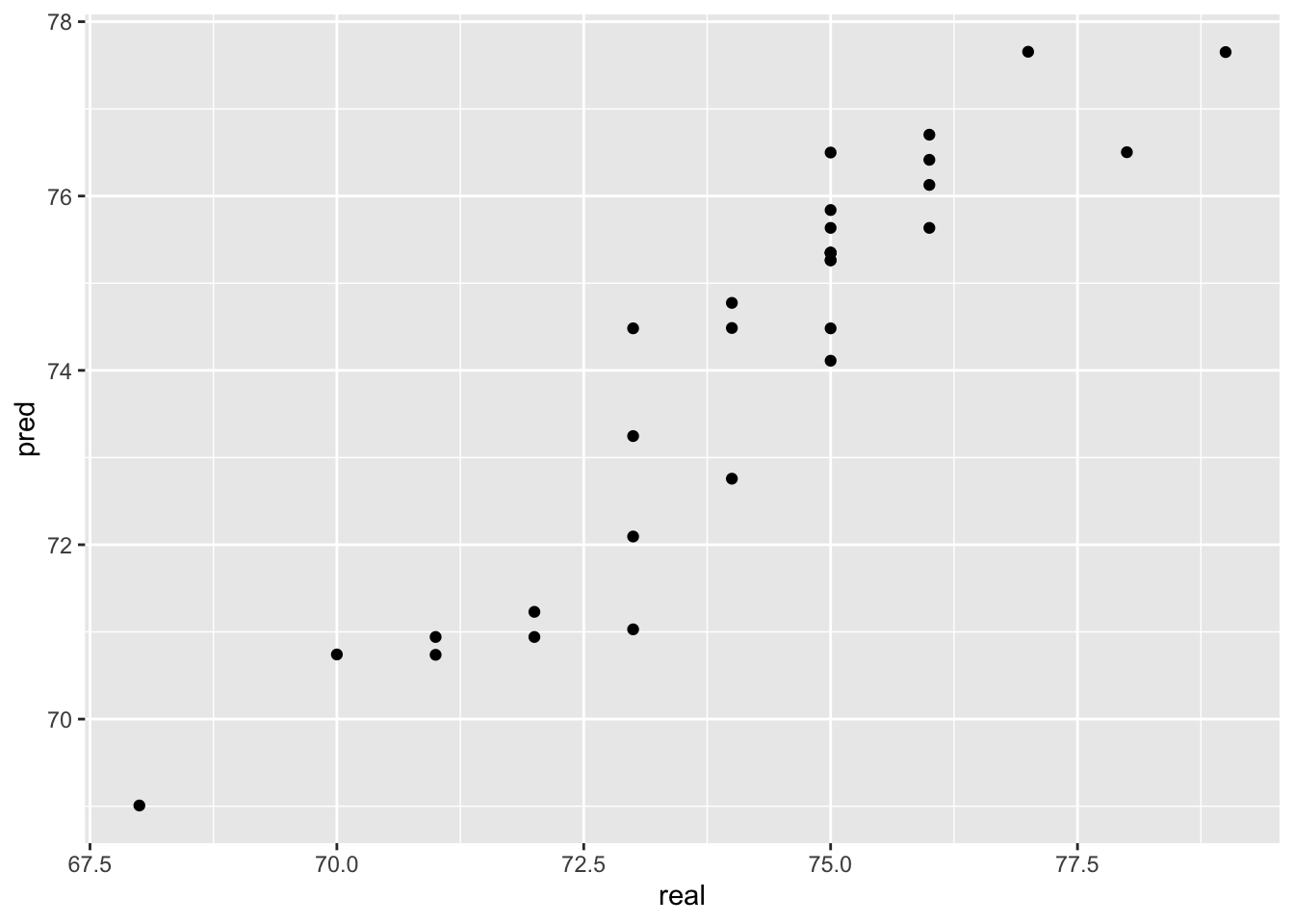
Not too bad! We usually calculate the root mean square error (rmse) between predictions and the true observed values to numerically evaluate regression performance:
RMSE(pred$real,pred$pred)[1] 0.8740346Our predictions are on average 0.87 years ‘off’.
Part2: Logistic Regression
Classification is the method we use when the outcome variable we are interested in is not continuous, but instead consists of two or more classes.
In order to have a categorical outcome, we’ll add a column to our toy data that describes whether the person died before age 75 or not.
df_smoke <- df_smoke %>%
mutate(early_death = factor(ifelse(life < 75, 1, 0))) # Encoding: True/yes = 1, False/no = 0
df_smoke %>%
count(early_death)# A tibble: 2 × 2
early_death n
<fct> <int>
1 0 49
2 1 51Training and Test set with class data
Let’s remake our training and test data. This time we have classes that we would like to be in the same ratios in training and test set. We must check this is the case!
# Set seed to ensure reproducibility
set.seed(100)
#add an ID column to keep track of observations
df_smoke$ID <- 1:nrow(df_smoke)
train <- df_smoke %>%
sample_frac(0.70)
table(train$early_death)
0 1
34 36 test <- anti_join(df_smoke, train, by = 'ID')
table(test$early_death)
0 1
15 15 Luckily for us the division of the outcome variable classes between the train and test set is almost perfect. However, there may be cases where randomly splitting will not give you a balanced distribution. This is likely to happen if one class is much larger than the other(s). In these cases you should split your data in a non-random way, specifically ensuring a balanced train and test set.
Now let’s perform logistic regression to see whether there is an influence of the number of cigarettes and amount of exercise on the odds of the person dying before 75.
Logistic regression belongs to the family of generalized linear models. They all look like this:
\[ y \sim \beta * X \]
with:
- \(y\) the outcome
- \(\beta\) the coefficient matrix
- \(X\) the matrix of predictors
- \(\sim\) the link function
In a logistic regression model the link function is the logit. In a linear model the link function is the identity function (so ~ becomes =).
Logistic regression: Math
In order to understand what that means we’ll need a tiny bit of math.
Our \(y\) is either 0 or 1. However we cannot model that, so instead we will model the probability of the outcome being 1: \(P(earlydeath == 1)\). This means that all \(y's\) have to be between these two values and how are we gonna enforce that? We wont.
Instead, we will model the log-odds of early death:
\[ y = \log(\frac{P(earlydeath == 1)}{1-P(earlydeath == 1)})\]
It may not look like it but we promise you this \(y\) is a well behaved number because it can be anywhere between - infinity and + infinity. So therefore our actual model is:
\[ y \sim \beta * X\]
\[ \log(\frac{P(earlydeath == 1)}{1-P(earlydeath == 1)} = \beta * X\]
And if we want to know what this means for the probability of dying early, we just take and invert the link function:
\[ P(earlydeath == 1) = \frac{e^{(\beta * X)}}{1+ e^{(\beta * X)}} \]
Which can be shortened to:
\[ P(earlydeath == 1) = \frac{1}{1+ e^{(-y)}} \]
Which serves as the link between what we’re actually interested in (the probability of a person dying early) and what we’re modelling using logit. End of math.
Model formulation in R
So in order to fit a logistic regression we will use the function for generalized linear models, glm. We will specify that we want logistic regression (using the logit as the link) by setting family = binomial:
model_log <- glm(early_death ~ daily_cigarettes + exercise, data = train, family = "binomial")
summary(model_log)
Call:
glm(formula = early_death ~ daily_cigarettes + exercise, family = "binomial",
data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -12.378 4.888 -2.532 0.0113 *
daily_cigarettes 1.113 0.439 2.536 0.0112 *
exercise1 -3.055 1.917 -1.594 0.1110
exercise2 -6.818 3.198 -2.132 0.0330 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 96.983 on 69 degrees of freedom
Residual deviance: 14.697 on 66 degrees of freedom
AIC: 22.697
Number of Fisher Scoring iterations: 9Model interpretation
We see from looking at the summary that the coefficient of exercise level 1 and level 2 is not significant. This means that we are not confident that doing any level of exercise has a significant impact on the probability of dying before 75 compared to doing no exercise.
Are you surprised? Exercise level was significant when we modelled the number of years lived with linear regressions.
With the number of daily cigarettes predictor we have a high degree of certainty that it influences the probability of dying before 75 (in this dataset!), but what does a coefficient of 1.1 mean?
We know that:
\[ P(earlydeath == 1) = \frac{1}{1+ e^{(-y)}} \]
and (leaving out the exercise level since it’s not significant):
\[ y = \beta_0 + \beta_1 * cigs \]
So how does \(y\) change as \(1.1 * cigs\) becomes larger? Let’s agree that \(y\) becomes larger. What does that mean for the probability of dying before 75? Is \(e^{(-y)}\) a large number if \(y\) is large? Luckily we have a calculator handy:
#exp(b) is e^b in R
exp(-1)[1] 0.3678794exp(-10)[1] 4.539993e-05exp(-100)[1] 3.720076e-44We see that \(e^{(-y)}\) becomes increasingly smaller with larger \(y\) which means that:
\[ P(earlydeath == 1) = \frac{1}{1+ small} \sim \frac{1}{1} \]
So the larger \(y\) the smaller \(e^{(-y)}\) and the closer we get to \(P(earlydeath == 1)\) being 1. That was a lot of math for: If the coefficient is positive you increase the likelihood of getting the outcome, i.e. dying before 75.
Model comparison
Now we know how to fit linear models and interpret the results. But often there are several predictors we could include or not include, so how do we know that one model is better than another?
There are several ways to compare models.
One is the likelihood ratio test which tests whether adding predictors significantly improves model fit by comparing the log-likelihoods of the two models.
Another very used way of comparing models is to look at the AIC (Akaike Information Criterion) or BIC (Bayesian Information Criterion). Lower AIC/BIC values generally indicate a better trade-off between model fit and complexity.
For example we made this logistic regression model above:
summary(model_log)
Call:
glm(formula = early_death ~ daily_cigarettes + exercise, family = "binomial",
data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -12.378 4.888 -2.532 0.0113 *
daily_cigarettes 1.113 0.439 2.536 0.0112 *
exercise1 -3.055 1.917 -1.594 0.1110
exercise2 -6.818 3.198 -2.132 0.0330 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 96.983 on 69 degrees of freedom
Residual deviance: 14.697 on 66 degrees of freedom
AIC: 22.697
Number of Fisher Scoring iterations: 9But exercise1 does not have a significant p-value. Perhaps we would have a better model if we only use dialy_cigarettes?
Let’s compare them:
model_reduced <- glm(early_death ~ daily_cigarettes, data = train, family = "binomial")
summary(model_reduced)
Call:
glm(formula = early_death ~ daily_cigarettes, family = "binomial",
data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.0494 2.2472 -3.582 0.000341 ***
daily_cigarettes 0.5473 0.1573 3.479 0.000503 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 96.983 on 69 degrees of freedom
Residual deviance: 25.269 on 68 degrees of freedom
AIC: 29.269
Number of Fisher Scoring iterations: 7We can use an anova with the Chi-square (kai-square) test to compare the log-likelihood of the two models. It is most common to compare the less complex model to the more complex model:
anova(model_reduced, model_log, test = 'Chisq')Analysis of Deviance Table
Model 1: early_death ~ daily_cigarettes
Model 2: early_death ~ daily_cigarettes + exercise
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 68 25.269
2 66 14.697 2 10.572 0.005063 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The p-value of the Chi-square test tells us that there is evidence that the difference in log-likelihoods is significant. If it is not significant we would choose the less complex model with fewer predictors since that gives us more statistical power and less overfitting.
In our case the p-value is significant indicating that the model with exercise might in fact be better even if Exercise level 1 was not significant in the model.
Model Evaluation
Lastly, let’s evaluate our model using the test set, just like we did for the linear regression. First, we will predict the outcome for the test set:
y_pred <- predict(model_log, newdata = test, type = 'response')
y_pred 1 2 3 4 5 6
3.962107e-02 1.577947e-04 3.011396e-02 9.999982e-01 9.999994e-01 9.998222e-01
7 8 9 10 11 12
9.999937e-01 1.000000e+00 9.999959e-01 1.000000e+00 9.967238e-01 8.635532e-02
13 14 15 16 17 18
9.999617e-01 9.999998e-01 4.210456e-06 9.998835e-01 9.999996e-01 1.115755e-01
19 20 21 22 23 24
9.704404e-01 1.034160e-04 4.210456e-06 3.956490e-07 3.962107e-02 2.909117e-03
25 26 27 28 29 30
4.210456e-06 9.151439e-01 6.037235e-07 9.999986e-01 1.299707e-07 1.000000e+00 As you see, the predictions we get out are not \(yes\) or \(no\), they are instead a probability (as discussed above), so, we will convert them to class labels.
y_pred <- ifelse(as.numeric(y_pred) >= 0.5, 1, 0) %>%
as.factor()
y_pred [1] 0 0 0 1 1 1 1 1 1 1 1 0 1 1 0 1 1 0 1 0 0 0 0 0 0 1 0 1 0 1
Levels: 0 1Now we will compare the predicted class with the observed class for the test set. You can do this in different ways, but here we will use the accuracy.
\[ Accuracy = \frac{(True Positives + True Negatives)}{(True Positives + True Negatives + False Positives + False Negatives)}\]
You can calculate the accuracy yourself, or you can use a function like confusionMatrix() from the package caret which also provides you with individual metrics like sensitivity (true positive rate, recall) and specificity (true negative rate).
caret::confusionMatrix(y_pred, test$early_death)Confusion Matrix and Statistics
Reference
Prediction 0 1
0 14 0
1 1 15
Accuracy : 0.9667
95% CI : (0.8278, 0.9992)
No Information Rate : 0.5
P-Value [Acc > NIR] : 2.887e-08
Kappa : 0.9333
Mcnemar's Test P-Value : 1
Sensitivity : 0.9333
Specificity : 1.0000
Pos Pred Value : 1.0000
Neg Pred Value : 0.9375
Prevalence : 0.5000
Detection Rate : 0.4667
Detection Prevalence : 0.4667
Balanced Accuracy : 0.9667
'Positive' Class : 0